We recently experienced a massive slow down in one of our background jobs and tracked down the cause via redis tools to a cache clearing issue. I decided to write up how we tracked it down to share with other developers - but this blog post comes with a geekery warning : the target audience is definitely solidly in the developer space and assumes the reader has a lot of background knowledge.
The problem
Wikimedia has a process whereby we queue donations (taken via forms not directly linked to CiviCRM) into our database and then send thank you emails in a separate process. We do this because our absolute priority is to get donations into our database as quickly as possible so we have the donation queue processing running on every bit of CPU cycle we can scrape together - but it is also important to us that people receive their emails in a timely manner. Last month we sent out a fundraising email and saw that it was taking people hours, not minutes to get their thank you email. Put simply our thank you email process was not keeping up with our incoming donations.
Initial analysis
We have a bunch of performance graphs using grafana and from these we could see there had not been a lag in thank you email delivery until mid October. Looking at the logs of our outgoing emails we could see that we were sending less emails in each 3 minute run that we had under similar load in September. We added a lot of debug spam to our logs (we use Monolog) and saw that rather than there being one slow point in our processing there were multiple points in the processing where api calls had gone from taking a couple of milliseconds to 100 milliseconds. It was not specific api calls so we concluded that something about the api wrapper itself had slowed down. We were also able to identify that a civicrm point release deployment was timed about right to relate to the slow down. Oddly enough we did not see a slow down on our donation queue processing job - which also runs a lot of apiv4 actions, or on any other jobs.
Spinning our wheels
We did this for a bit - just have to put this step in there, least you think we skipped straight to figuring it out. However, a nights sleep & 3 cups of coffee later I was able to dig into the lost corners of my brain and get started on it.
What could it be?
Generally there were 4 levels on’ which we were thinking about performance
- Mail hand off - was there a lag in handing off to the email server. Our log debugging didn’t show this to be the slow point
- SQL - we weren’t seeing any slow queries and we were not seeing slowness on other jobs + the log spam was telling us that very light api calls were slow
- PHP - profiling php is hard - we were gearing up to do this when I decided I'd had enough coffee to switch to looking at …
- Cache issue (spolier alert - this is where I found the issue & the rest of this post is gonna talk about how I was able to see a problem using Redis tools).
Delving into Redis
We use Redis for our caches and while the issue ultimately affected all caches it was with Redis tools we figured it out.
Redis cache has a tool to monitor redis - called, erm, monitor - ie
redis-cli monitor
Unfortunately the output from this is pretty intense ….You hit a wall of text like this
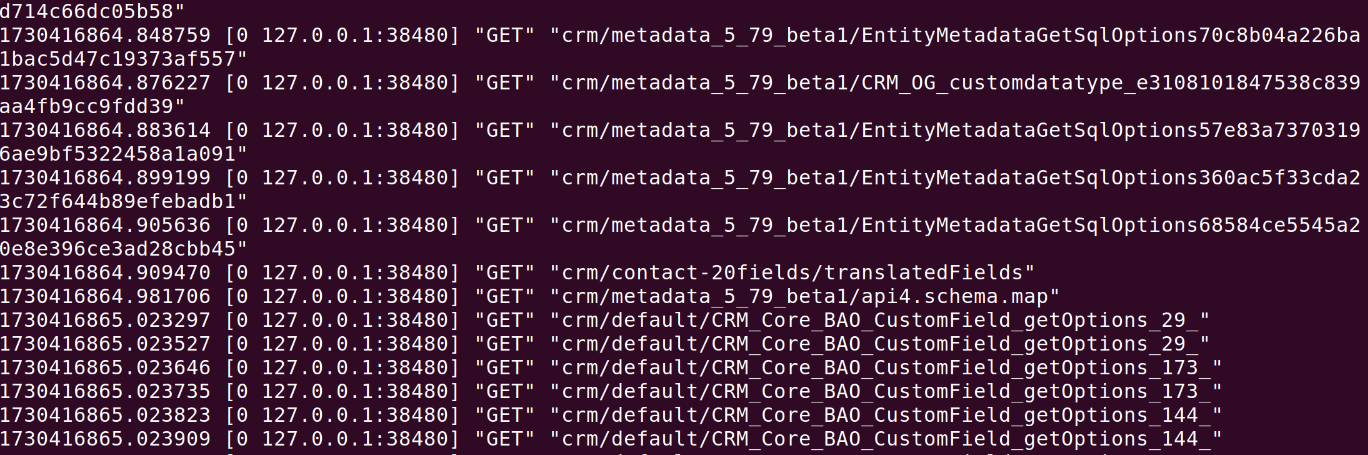
I had 27 MB of rows like that from the few seconds I turned it on. In the image above you see 127.0.0.1:38340 repeated. 38340 is the connection ID and in the real log sample there were dozens of connections on the go so unlike in the above snippet it wasn’t possible to see the flow of cache hits from a single connection.
Fortunately this was not my first rodeo. I already had an extension I put in the oven earlier that could help me parse this output. Ie once it is downloaded… using these commands
cv en systemtools
redis-cli monitor > /tmp/redis.log
cv api4 Redislog.parse fileName=/tmp/redis.log
This gives us some output with some immediate clues that something is wrong. The screenshot below shows the first part of the output. Under ‘duplicate_hits’ we see that connection 56668 did 59 GET calls and 58 SET calls on a single key in the metadata cache.

So what does that mean?
Well CiviCRM has a bunch of different caches defined here - in the above output we can see two in action - the line GET - crm/settings is the settings cache - referred to in codes as \Civi::cache('settings'); whereas the GET - crm/metadata is the metadata cache - \Civi::cache('metadata')
.
Both of these caches are ‘fastArray’ caches - which means that once the date for a given cache key has been returned once, is it stored in a php array for the rest of the php process - so in most php requests there should be only one call to the Redis cache for each key.. So, why is it not getting the values from the php array cache?
This is where the second part of the command line output comes into play - all the log lines have been output to a file called “redis_parsed.log” (per the output above). Once I open that file in Excel I can use some basic filtering to see what is happening with a given process. There are two things I’m looking for - either signs of the fast array cache being bypassed or signs of excessive cache clears. In the output below I see the latter - the ‘DEL’ (delete) action appear repeatedly. That tells me that the metadata cache is being cleared multiple times in the course of the process - requiring it to be rebuilt repeatedly.
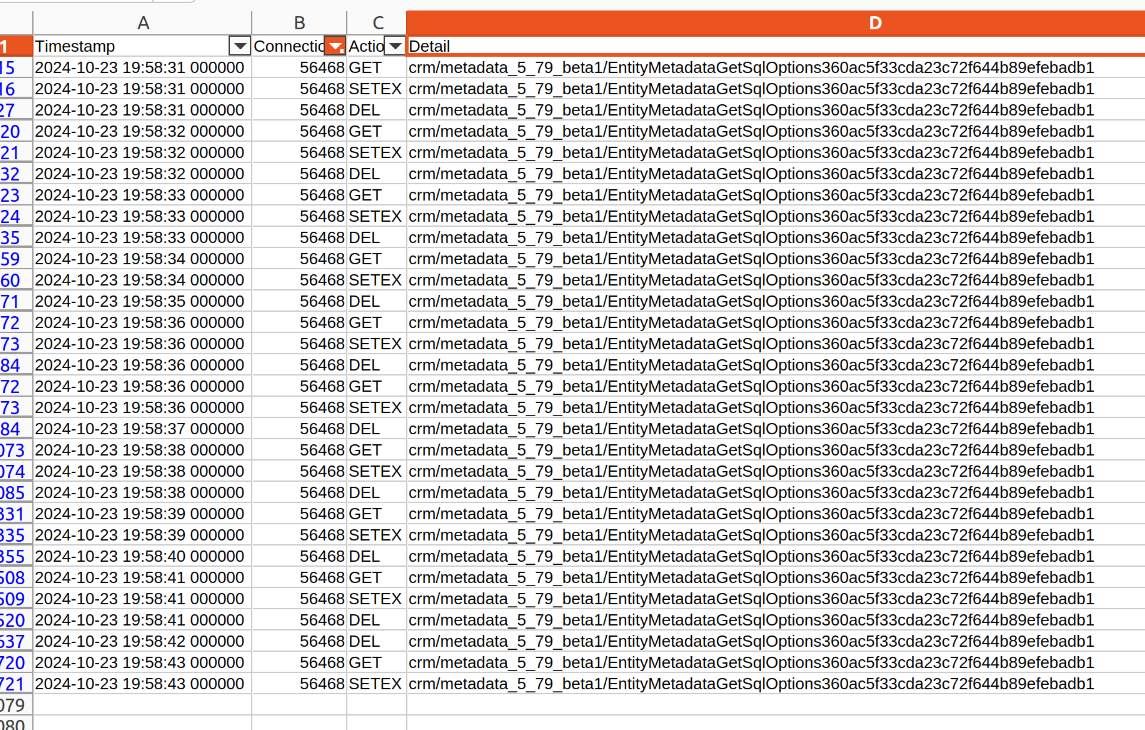
So - I know what I’m looking for for is the metadata cache being cleared excessively so time to poke around in the code for when it is cleared
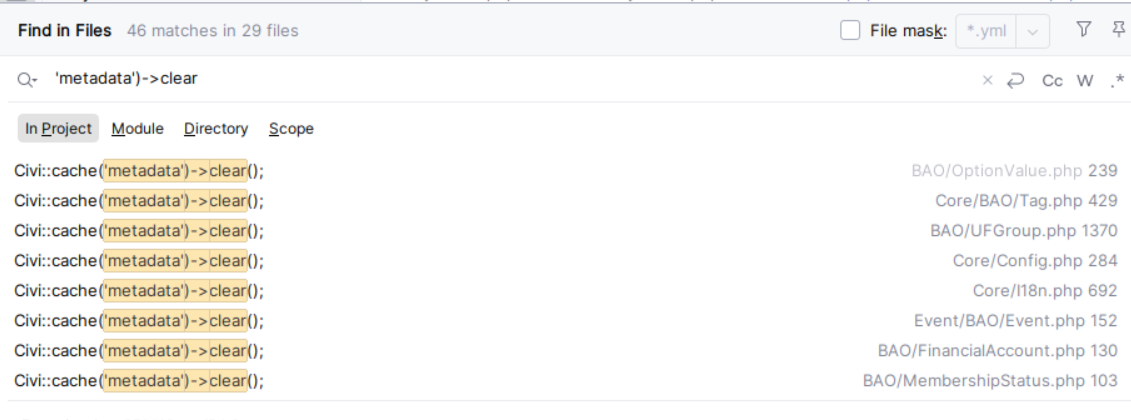
(there were some calls to the legacy function too)
From here I poked around & when I got to the I18n file I saw that the code had been updated recently enough to have changed in our last code deploy (since we upgrade often we only had to look back up to 2 months)

And I was able to find the commit on github
We tested removing that line and our processing rate quintupled immediately.
Wrapping up
I’m not going to go into the details of why that change was made or my (current) efforts to put up a more durable fix as the goal of this blog was to talk through some of the techniques I use to get to the bottom of an obscure performance issue.
I would note, however, that on finding the issue was in the `setLocale()` function it made sense why we experience a slow down on sending letters compared to processing donations - swapLocale() is called in a couple of places in the process of rendering correspondence.
Comments
Thanks Eileen, I appreciate you sharing the details (especially the part about the night of sleep and coffee). I'm not sure I have ever solved a hard problem without both!